
¡Hola, soy Leo Byte! Como desarrollador senior, he navegado por un océano de herramientas, pero pocas son tan transformadoras como Jupyter Notebook.
Recuerdo perfectamente los días de scripts desordenados y resultados perdidos en la consola. Jupyter cambió mi forma de trabajar, convirtiendo el código en una historia interactiva.
En este tutorial de Jupyter Notebook, quiero ser tu “Nauta” principal, guiándote para que entiendas cómo usar Jupyter Notebook desde la instalación hasta tu primer análisis de datos, para que tú también domines esta herramienta esencial. ¡Empecemos! 🚀
¿Qué es Jupyter Notebook y Para Qué Sirve?
Jupyter Notebook es una aplicación web de código abierto que te permite crear y compartir documentos interactivos. Estos combinan código ejecutable, ecuaciones, visualizaciones y texto explicativo en un solo lugar. Es ideal para análisis de datos, machine learning y educación, ya que muestra tanto el proceso como los resultados de forma clara y reproducible.
Jupyter Notebook es una aplicación web de código abierto que permite crear y compartir documentos que contienen código en vivo, ecuaciones, visualizaciones y texto narrativo. En esencia, es un entorno de desarrollo interactivo donde el código y los resultados de su ejecución se encuentran en el mismo lugar.
Nota importante: En esta guía me centraré en la interfaz clásica de Jupyter Notebook, que es perfecta para aprender. Sin embargo, al instalar el ecosistema Jupyter hoy en día, también obtendrás JupyterLab, el entorno de nueva generación más potente y flexible. ¡No te preocupes! Todo lo que aprendas aquí es 100% aplicable a ambos.
El nombre “Jupyter” se deriva de los tres lenguajes de programación principales que soporta esta plataforma: Julia, Python y R. Sin embargo, ¡hoy en día Jupyter es compatible con más de 40 lenguajes de programación!
Principales ventajas de Jupyter Notebook:
- Interactividad: El código se ejecuta por fragmentos y los resultados se muestran de inmediato.
- Claridad visual: Permite combinar código, texto, imágenes y gráficos.
- Documentación integrada: Un notebook finalizado es a la vez código y documentación.
- Reproducibilidad: Cualquier persona puede ejecutar tu notebook y obtener los mismos resultados.
- Exportación: Permite guardar el trabajo en diversos formatos (HTML, PDF, presentaciones).
Jupyter Notebook se utiliza activamente en las siguientes áreas:
| Área de aplicación | Uso | Ventajas |
|---|---|---|
| Análisis de datos | Procesamiento, visualización e interpretación de datos. | Representación clara de cada paso del análisis. |
| Machine Learning | Desarrollo y prueba de modelos. | Posibilidad de experimentar con parámetros y visualizar resultados. |
| Educación | Creación de materiales de aprendizaje interactivos. | Los estudiantes pueden ejecutar código paso a paso y experimentar. |
| Investigación científica | Documentación de experimentos y análisis. | Reproducibilidad de la investigación, transparencia de la metodología. |
Cómo Instalar Jupyter Notebook: Guía Paso a Paso
La instalación de Jupyter Notebook es relativamente sencilla, aunque puede variar según el sistema operativo y las preferencias del usuario. A continuación, describo varios métodos de instalación. 🛠️
Método 1: Instalación mediante Anaconda (recomendado para principiantes)
Anaconda es una distribución de Python que incluye Jupyter Notebook y muchos otros paquetes útiles para la computación científica y el análisis de datos.
- Accede al sitio web de Anaconda y descarga el instalador para tu sistema operativo.
- Ejecuta el archivo descargado y sigue las instrucciones del instalador.
- Una vez finalizada la instalación, inicia Anaconda Navigator, una interfaz gráfica que permite gestionar aplicaciones, incluido Jupyter Notebook.
- En Anaconda Navigator, haz clic en el botón “Launch” debajo de Jupyter Notebook para que se abra en tu navegador.
Método 2: Instalación mediante pip (gestor de paquetes estándar de Python)
Si ya tienes instalado Python (versión 3.3 o superior), puedes instalar Jupyter Notebook a través de pip:
- Abre la línea de comandos (Terminal en macOS/Linux o Command Prompt en Windows).
- Introduce el comando:
pip install notebook - Una vez completada la instalación, introduce:
jupyter notebook - El navegador se abrirá automáticamente con Jupyter Notebook.
Método 3: Uso de entornos virtuales (para usuarios avanzados)
Si deseas aislar Jupyter Notebook de otros proyectos, puedes utilizar un entorno virtual:
- Crea un entorno virtual:
python -m venv myenv - Actívalo:
- Windows:
myenv\Scripts\activate - macOS/Linux:
source myenv/bin/activate
- Windows:
- Instala Jupyter:
pip install notebook - Inicia Jupyter:
jupyter notebook
Verificación de la instalación
Independientemente del método de instalación elegido, Jupyter Notebook debería abrirse en tu navegador en la dirección http://localhost:8888. Si el navegador no se abre automáticamente, copia la URL del terminal y pégala en la barra de direcciones.
Comparación de métodos de instalación para diferentes escenarios:
| Método de instalación | Adecuado para | Ventajas | Desventajas |
|---|---|---|---|
| Anaconda | Principiantes, analistas de datos | Incluye múltiples paquetes, interfaz gráfica | Ocupa mucho espacio (~3 GB) |
| Pip | Desarrolladores de Python | Ligero, rápido, minimalista | Requiere instalar dependencias por separado |
| Entornos virtuales | Profesionales que trabajan en múltiples proyectos | Aislamiento de dependencias, entorno limpio | Mayor complejidad en configuración y gestión |
| Google Colab (solución en la nube) | Principiantes, usuarios que no desean instalar software | No requiere instalación, acceso por internet | Requiere conexión a internet, limitaciones en la versión gratuita |
Dominando la Interfaz: Funciones Clave y Shortcuts
Al iniciar Jupyter Notebook, verás una interfaz web denominada “Dashboard” (Panel de control). Este es tu punto de partida para crear y gestionar archivos notebook. Analicemos los elementos principales de la interfaz y su funcionalidad. 🔍
Panel de control (Dashboard)
- Pestañas: Files (Archivos), Running (En ejecución), Clusters (Clústeres).
- Files: Muestra la estructura de carpetas y archivos, desde donde puedes crear nuevos notebooks.
- Running: Muestra una lista de los notebooks y terminales en ejecución.
- Botón New: Permite crear un nuevo notebook, archivo de texto o carpeta.
- Upload: Permite cargar archivos desde tu ordenador.
Interfaz del notebook
Al crear o abrir un notebook, verás el entorno de trabajo con los siguientes elementos:
- Título: Por defecto es “Untitled”. Puedes cambiarlo haciendo clic sobre él.
- Menú: File, Edit, View, Insert, Cell, Kernel, Widgets, Help.
- Barra de herramientas: Contiene botones para trabajar con celdas y ejecutar código.
- Área de trabajo: Compuesta por celdas donde se introduce el código y el texto.
Tipos de celdas
Jupyter Notebook admite varios tipos de celdas, cada una con un propósito específico:
- Code: Para escribir y ejecutar código.
- Markdown: Para texto con formato (títulos, listas, fórmulas).
- Raw NBConvert: Texto sin procesar que no se ejecuta.
- Heading (obsoleto): Anteriormente se usaba para títulos, ahora se recomienda usar Markdown.
Atajos de Teclado (Shortcuts)
Dominar los Jupyter Notebook shortcuts aumenta significativamente tu eficiencia y velocidad. Aquí tienes los más importantes:
- Shift + Enter: Ejecuta la celda actual y pasa a la siguiente.
- Ctrl + Enter: Ejecuta la celda actual y permanece en ella.
- Alt + Enter: Ejecuta la celda y crea una nueva debajo.
- Esc: Cambia a modo de comando (borde azul).
- Enter: Cambia a modo de edición (borde verde).
- A (en modo de comando): Inserta una celda arriba.
- B (en modo de comando): Inserta una celda abajo.
- DD (doble pulsación de D en modo de comando): Elimina la celda.
- M: Convierte la celda a tipo Markdown.
- Y: Convierte la celda a tipo Code.
Trabajo con el Kernel
El kernel es el proceso que ejecuta el código en el notebook. Las operaciones principales con el kernel son:
- Restart: Reinicia el kernel (útil en caso de errores o bloqueos).
- Interrupt: Interrumpe la ejecución del código (si el código entra en un bucle infinito).
- Restart & Clear Output: Reinicia el kernel y borra todas las salidas.
- Restart & Run All: Reinicia el kernel y ejecuta todas las celdas.
- Change kernel: Cambia el lenguaje de programación (si hay otros kernels instalados).
Extensiones (Extensions)
Jupyter Notebook se puede ampliar con complementos que añaden funcionalidades:
- Instalación vía pip:
pip install jupyter_contrib_nbextensions - Configuración:
jupyter contrib nbextension install --user - Activación: En la pestaña Nbextensions del Dashboard de Jupyter.
Algunas extensiones populares incluyen Table of Contents (índice), Collapsible Headings (títulos plegables) y Variable Inspector (inspector de variables), entre otras.
Tu Primer Proyecto: Un Ejemplo Práctico con Python
Ahora que conocemos la interfaz, vamos a ver un ejemplo de Jupyter Notebook en acción creando nuestro primer proyecto. Te guiaré en el proceso de creación de un documento de análisis simple con código, explicaciones textuales y visualización de datos. Este es un perfecto Jupyter Notebook Python example. 📊
Antes de empezar, una anécdota personal: en uno de mis primeros trabajos, me encargaron analizar los patrones de tráfico de una red. Tenía un script de Python que generaba logs y otro para visualizarlos. Era un caos. Al presentar los resultados, mi jefe me pidió un pequeño cambio en un parámetro. Tuve que volver a ejecutar todo, regenerar los gráficos y montar un nuevo informe. Tardé una hora. Un colega me mostró cómo hacerlo en Jupyter. La siguiente vez que me pidieron un cambio, modifiqué una celda, la ejecuté y mostré el nuevo gráfico en 15 segundos. Esa fue la “victoria” que me convirtió en un evangelista de esta herramienta.
Paso 1: Crear un nuevo notebook
- Inicia Jupyter Notebook desde la línea de comandos o Anaconda Navigator.
- En el panel de control, haz clic en el botón “New” en la esquina superior derecha.
- Selecciona “Python 3” (u otra versión disponible).
- Se abrirá un nuevo notebook con una celda de código vacía.
- Haz clic en “Untitled” en la parte superior y cambia el nombre del archivo, por ejemplo, a “Mi primer análisis”.
Paso 2: Documentar con Markdown en Jupyter Notebook
Un buen análisis siempre está bien documentado. El primer paso es aprender a usar Markdown en Jupyter Notebook para crear un título y una descripción para nuestro proyecto:
- Haz clic en la primera celda y selecciona “Markdown” en el menú desplegable de la barra de herramientas.
- Introduce el siguiente texto (puedes consultar una guía rápida de Markdown si lo necesitas):
# Análisis del conjunto de datos Iris
## Introducción al análisis de datos con Jupyter Notebook
En este proyecto, analizaremos el clásico conjunto de datos Iris (Iris de Fisher), que contiene mediciones de pétalos y sépalos de tres especies de iris.
**Objetivos del análisis:**
- Cargar y examinar la estructura de los datos.
- Realizar un análisis estadístico básico.
- Visualizar distribuciones y dependencias.
- Extraer conclusiones basadas en el análisis.- Presiona Shift+Enter para ejecutar la celda y ver el texto formateado.
Paso 3: Importar las librerías necesarias
Añade una nueva celda (haz clic en el botón “+” de la barra de herramientas) e importa las librerías para el análisis de datos:
# Importamos las librerías necesarias
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Configuramos la visualización de gráficos dentro del notebook
%matplotlib inline
# Establecemos un estilo para los gráficos
sns.set(style="whitegrid")Presiona Shift+Enter para ejecutar el código. Si las librerías no están instaladas, verás un mensaje de error. En ese caso, instálalas desde la línea de comandos: pip install pandas numpy matplotlib seaborn
Paso 4: Carga de datos
Crea una nueva celda para cargar el conjunto de datos Iris, disponible en la librería scikit-learn:
# Cargamos los datos Iris desde la librería scikit-learn
from sklearn.datasets import load_iris
# Cargamos el conjunto de datos
iris = load_iris()
# Creamos un DataFrame a partir de los datos con Pandas
# Puedes aprender más sobre Pandas en su documentación oficial - https://pandas.pydata.org/
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = [iris.target_names[i] for i in iris.target]
# Visualizamos las primeras 5 filas de los datos
df.head()Tras la ejecución, verás una tabla con las primeras 5 filas de los datos.
Paso 5: Análisis exploratorio de datos
Añade una celda con código para el análisis básico:
# Verificamos las dimensiones de los datos
print(f"Dimensiones del dataset: {df.shape}")
# Estadísticas básicas
print("\nIndicadores estadísticos:")
df.describe()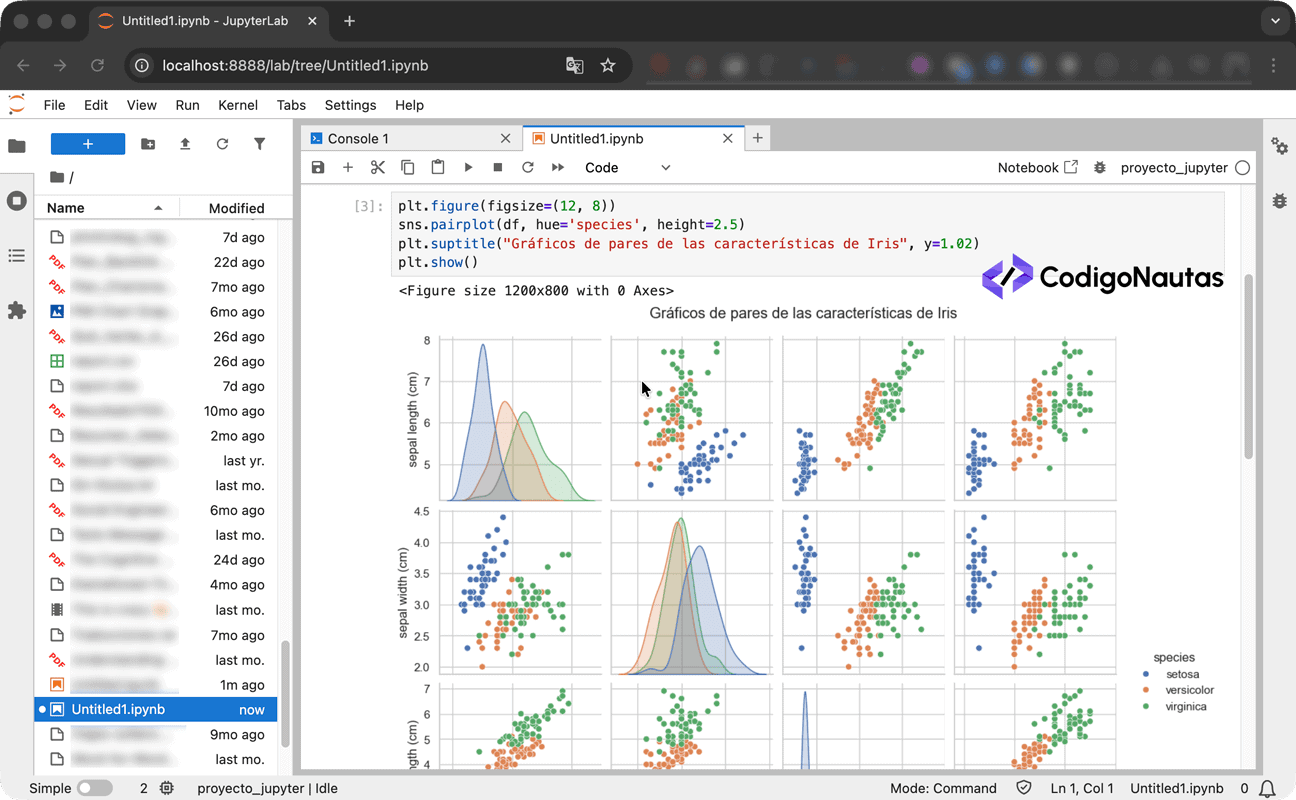
Paso 6: Visualización de datos
Crea una celda para visualizar las distribuciones usando la librería Seaborn:
# Creamos gráficos de pares para todas las características, diferenciando por especie
plt.figure(figsize=(12, 8))
sns.pairplot(df, hue='species', height=2.5)
plt.suptitle("Gráficos de pares de las características de Iris", y=1.02)
plt.show()Tras la ejecución, verás una matriz de gráficos que muestra las relaciones entre los diferentes parámetros de las flores, similar a la imagen anterior. Este tipo de visualización es uno de los puntos fuertes que este Jupyter Notebook tutorial busca destacar.
Paso 7: Análisis y conclusiones
Crea otra celda Markdown para resumir los resultados del análisis:
## Conclusiones
Del análisis realizado, se pueden extraer las siguientes conclusiones:
1. El conjunto de datos contiene 150 muestras de iris de tres especies: setosa, versicolor y virginica.
2. Para cada flor se miden 4 parámetros: longitud y anchura del sépalo, y longitud y anchura del pétalo.
3. La especie setosa es fácilmente separable de las otras dos según los parámetros del pétalo.
4. Las especies versicolor y virginica presentan cierta superposición, pero también pueden ser diferenciadas.
5. Los parámetros del pétalo (petal length y petal width) son más informativos para distinguir las especies que los del sépalo.Paso 8: Guardar los resultados
Jupyter Notebook guarda tu trabajo automáticamente cada pocos minutos, pero también puedes guardarlo manualmente:
- Presiona Ctrl+S o selecciona File → Save and Checkpoint en el menú.
- Para exportar a otros formatos: File → Download as → selecciona el formato deseado (HTML, PDF, Python, etc.).
Técnicas básicas para un trabajo eficiente en tu primer proyecto:
- Estructura tu notebook: Divídelo en secciones lógicas con títulos.
- Comenta el código: Añade comentarios a las partes complejas.
- Verifica los datos: Estudia siempre la estructura y calidad de los datos antes de analizarlos.
- Utiliza Markdown: Explica tus acciones y conclusiones en celdas de texto.
- Visualiza los resultados: Los gráficos a menudo revelan patrones que no son evidentes en los números.
Casos de Uso Reales en Análisis de Datos
Jupyter Notebook es una herramienta de gran flexibilidad, utilizada para resolver una amplia variedad de tareas analíticas. A continuación, presento ejemplos concretos de su uso en proyectos reales. 💼
1. Limpieza y preprocesamiento de datos
La preparación de datos suele consumir hasta el 80% del tiempo en un proyecto. Jupyter Notebook es ideal para esta tarea por las siguientes razones:
- Procesamiento paso a paso con verificación de resultados en cada etapa.
- Visualización de distribuciones antes y después de las transformaciones.
- Documentación de las decisiones tomadas (ej. por qué se eliminaron ciertos valores atípicos).
# Comprobar la existencia de valores nulos
df.isnull().sum()
# Rellenar valores nulos con la media
df['column_name'].fillna(df['column_name'].mean(), inplace=True)
# Eliminar duplicados
df.drop_duplicates(inplace=True)
# Detección y tratamiento de valores atípicos (outliers)
Q1 = df['column_name'].quantile(0.25)
Q3 = df['column_name'].quantile(0.75)
IQR = Q3 - Q1
df_filtered = df[~((df['column_name'] < (Q1 - 1.5 * IQR)) |
(df['column_name'] > (Q3 + 1.5 * IQR)))]2. Análisis exploratorio de datos (EDA)
Jupyter Notebook es especialmente adecuado para el EDA gracias a su capacidad para explorar datos de forma interactiva:
- Generación de múltiples visualizaciones para identificar patrones.
- Filtrado y agrupación interactiva de datos.
- Formulación y validación de hipótesis sobre la marcha.

3. Creación de dashboards e informes interactivos
Mediante extensiones como ipywidgets, es posible crear controles interactivos:
import ipywidgets as widgets
from IPython.display import display
# Creamos un slider para seleccionar un rango de precios
# Más información sobre ipywidgets en la documentación oficial: https://ipywidgets.readthedocs.io/en/stable/
price_slider = widgets.IntRangeSlider(
value=[100, 500],
min=0,
max=1000,
step=10,
description='Precio:',
continuous_update=False
)
# Función para filtrar datos por precio
def filter_by_price(price_range):
filtered_data = df[(df['price'] >= price_range[0]) &
(df['price'] <= price_range[1])]
return filtered_data.shape[0]
# Vinculamos el slider con la función de actualización
widgets.interactive(filter_by_price, price_range=price_slider)4. Modelado y Machine Learning
Jupyter Notebook permite demostrar de forma clara todo el proceso de creación, entrenamiento y evaluación de modelos, algo crucial en proyectos de inteligencia artificial:
- Preparación de datos para el modelado.
- Entrenamiento de diferentes modelos y comparación de su rendimiento.
- Ajuste de hiperparámetros con visualización de resultados.
- Explicación del funcionamiento del modelo mediante gráficos y tablas.
5. Creación de investigaciones reproducibles
Para proyectos científicos y de investigación, Jupyter Notebook ofrece la posibilidad de crear experimentos completamente reproducibles, como este análisis del dataset Iris con PCA:
- Documentación de todo el proceso, desde los datos de origen hasta las conclusiones.
- Inclusión de fórmulas, referencias bibliográficas y explicaciones metodológicas.
- Posibilidad de que otros investigadores ejecuten el código y obtengan los mismos resultados.
Casos de uso reales de Jupyter Notebook por sector:
| Sector | Aplicación | Ventajas del uso de Jupyter |
|---|---|---|
| Finanzas | Análisis de riesgos, predicción de mercados, detección de fraudes. | Documentación del análisis para auditorías, actualización rápida de modelos. |
| Salud | Análisis de datos médicos, predicción de enfermedades. | Transparencia del análisis, inclusión de terminología y explicaciones médicas. |
| Marketing | Segmentación de clientes, pruebas A/B, análisis de embudos de venta. | Informes visuales para perfiles no técnicos, paneles interactivos. |
| Educación | Materiales didácticos, ejercicios prácticos. | Interactividad, combinación de teoría y práctica. |
| Astronomía | Análisis de datos de telescopios, modelado de procesos cósmicos. | Procesamiento de grandes volúmenes de datos, visualización de fenómenos complejos. |
Técnicas avanzadas para usuarios experimentados:
- Comandos mágicos: Comandos especiales que comienzan con
%o%%y amplían la funcionalidad de las celdas (ej.%timepara medir el tiempo de ejecución). - Integración con Git: Seguimiento de cambios en los notebooks mediante sistemas de control de versiones como Git.
- Cómputo en paralelo: Uso de
IPython.parallelpara distribuir tareas entre los núcleos del procesador. - Conexión a bases de datos: Acceso directo a datos desde bases de datos SQL o NoSQL.
- Generación automática de informes: Configuración de un planificador para ejecutar notebooks periódicamente y enviar informes.
Consejos para la organización eficiente de proyectos de análisis:
- Divide proyectos complejos en varios notebooks, cada uno con una tarea específica.
- Utiliza plantillas para estandarizar el análisis.
- Crea la documentación del proyecto directamente en el notebook.
- Guarda puntos de control (checkpoints) regularmente y exporta los resultados.
- Optimiza el código para trabajar con grandes conjuntos de datos.
Tu Viaje con Jupyter Apenas Comienza
Jupyter Notebook transforma el enfoque del análisis de datos, convirtiéndolo de un proceso lineal en una exploración interactiva. Al dominar las habilidades básicas de instalación y uso que hemos visto en este tutorial, obtendrás una plataforma potente para resolver tareas analíticas de cualquier complejidad.
Desde tus primeros pasos en Python hasta el machine learning avanzado, Jupyter crecerá junto a tus habilidades. Comienza con algo pequeño: crea tu primer notebook, experimenta con el código y la visualización, y pronto descubrirás que esta herramienta se ha convertido en una parte esencial de tu arsenal analítico.
