
Una de las maneras más sencillas de mejorar el rendimiento general de una base de datos, y más concretamente, el rendimiento de las consultas, es usar índices de bases de datos.
Pero aquí lo principal es elegir el tipo de índice correcto. Cada índice en SQL tiene sus propias ventajas, y por eso es importante saber cuándo y qué índice usar. Aquí veremos los índices más comunes de los sistemas de gestión de bases de datos relacionales (SGBD) más populares y averiguaremos cuándo debemos usarlos.
¿Qué son los índices de bases de datos?
Un índice de base de datos es una estructura de datos adicional que se crea junto con los datos en una tabla. Defines un índice para una tabla y una columna (o un conjunto de columnas). De este modo, creas una nueva estructura de búsqueda de datos que está directamente relacionada con esa tabla y el conjunto de columnas.
En este artículo, explicaremos detalladamente qué es un índice, cómo se puede crear, qué tipos de índices existen y cuándo deben utilizarse.
¿Para qué sirven los índices?
Los índices de bases de datos aceleran el proceso de extracción de datos y, por lo tanto, mejoran el rendimiento de las consultas. Esta es la principal función de dichos índices. Todo esto ocurre porque se asigna memoria adicional para almacenar el árbol B+ y los punteros a los datos reales.
Los índices se utilizan para que, en cada consulta de filas de una tabla, la base de datos no tenga que examinar todas las filas. En general, los índices proporcionan una forma bastante eficaz de acceder a registros ordenados.
¿Cómo se puede crear un índice?
Los diferentes SGBD tienen una sintaxis diferente para crear un índice. Además, los diferentes mecanismos de SGBD utilizan diferentes parámetros para ello. Esto lo veremos más adelante. Sin embargo, existe una sintaxis general para crear el índice más primitivo, que es adecuada para todos los mecanismos de SGBD. A continuación, se muestra la estructura sintáctica con la que se puede crear el índice más primitivo en una tabla.
CREATE INDEX nombre_índice
ON nombre_tabla (nombre_columna_1, nombre_columna_2, …)Ahora, utilicemos esta estructura para crear un índice para una tabla real. Supongamos que tenemos una tabla Customer (ver más abajo), y queremos crear un índice para acelerar el proceso de búsqueda por nombre de cliente.

CREATE INDEX IX_CustomerName
ON Customer (FirstName, LastName)Una vez ejecutado este código, obtendremos un índice para la tabla Customer llamado IX_CustomerName. Gracias a este índice, la búsqueda de datos en las columnas FirstName y LastName será mucho más rápida.
El índice que se crea, por así decirlo, entre bastidores, también se denomina índice no agrupado o índice estándar. Con este índice, podemos ejecutar consultas optimizadas para escenarios en los que hay consultas como:
SELECT FirstName, LastName, Email
FROM Customer
WHERE Nombre = 'Marcos' and LastName = 'Diaz'La experiencia demuestra que, cada vez que queremos optimizar una consulta, observamos las columnas que se utilizan para extraer datos y comprobamos si tenemos un índice para ellas. Si las columnas de la cláusula SELECT son similares a las columnas de las cláusulas para la extracción de datos, tenemos un plan de acción optimizado y, por consiguiente, la búsqueda es más rápida.
Pero esto no es lo que necesitamos. La indexación es mucho más que estas reglas.
¿Qué tipos de índices hay en SQL?
Ya que hemos visto cómo crear un índice, ahora vamos a hablar de los tipos principales de índices de bases de datos relacionales, con los que podrás optimizar tus consultas. Algunos requieren un mecanismo de SGBD específico, por lo que indicaremos dónde se pueden usar.
Todos los índices almacenan punteros a las filas de datos en una estructura de datos llamada árbol de búsqueda. Esta estructura está optimizada para la búsqueda y es la principal base del índice. Con ella, podemos realizar algo parecido a una búsqueda en un árbol de búsqueda binario, pero en nuestro caso es algo más complejo.
Hay muchos índices diferentes. Cada uno tiene su propia estructura de datos interna y, por lo tanto, su función. Más adelante los veremos con más detalle, y aquí solo mencionaremos sus nombres brevemente.
Desde el punto de vista de las características del atributo:
- Índice principal
- Índice agrupado
- Índice secundario
Desde el punto de vista de la cantidad de referencias al archivo de datos:
- Índice denso
- Índice disperso
Índices no estándar para escenarios muy específicos:
- Índice de mapas de bits
- Índice inverso
- índice basado en funciones de hash
- Índice filtrado
- Índice por función
- Índice espacial
Para ilustrarlo, usaremos la misma tabla Customer que antes. Para entender cómo son los datos de ejemplo, escribamos una sencilla consulta SELECT y devolvamos todos los datos de la tabla.

Índice agrupado
Un índice agrupado (o de agrupación) es uno de los índices más comunes que se pueden usar en todos los SGBD modernos con todas las funciones. Este índice determina el orden en que se almacenan los datos en la página (físicamente) y en la tabla (implícitamente).
Veamos un ejemplo. Supongamos que las dos primeras filas se encuentran en la Página n.º 1, la tercera y la cuarta filas en la Página n.º 2, y la última, la quinta fila, en la Página n.º 3 (ver más abajo).

La función del índice agrupado es almacenar físicamente las filas en orden ascendente o descendente, tomando como base la columna que se ha elegido. Este índice sirve para almacenar precisamente los datos ordenados. Esto simplifica considerablemente la búsqueda de uno o varios valores en un rango determinado. Sin embargo, un índice agrupado solo puede ayudarnos si buscamos valores en un rango determinado, y no entre todos los datos.
Supongamos que la lista de clientes en nuestro panel de información siempre se muestra en orden alfabético. Queremos que nuestros datos se almacenen en nuestra base de datos ordenados por nombre y apellidos. Para crear un índice agrupado, escribimos la siguiente consulta:
CREATE CLUSTERED INDEX CI_FirstName_LastName
ON Customer (Nombre ASC, LastName ASC);Esta consulta afecta a la anterior, con la que devolvimos todos los datos. Cuando creamos un índice agrupado con ordenación ascendente por nombre y apellido, reordenamos físicamente los datos en las páginas. Si miramos nuestras páginas, veremos que ahora tienen un aspecto diferente:

Como vemos, ahora los datos están ordenados por nombre y luego por apellido. Esto puede simplificarnos mucho la vida y mejorar el rendimiento, ya que, si realizamos una consulta para ordenar las filas alfabéticamente, no ocurrirá nada, puesto que las filas ya están almacenadas en orden. De este modo, podemos prescindir de la ordenación en la propia consulta.
Si queremos obtener los datos de los 10 primeros clientes desde el punto de vista del orden alfabético, la base de datos no los buscará en toda la tabla. Simplemente devolverá las páginas con las 10 primeras entradas, ya que ya están ordenadas.
Índice de mapas de bits
Un índice de mapas de bits es otro tipo de índice. En el momento de escribir este artículo, solo se podía usar en Oracle. Este índice es especialmente útil en un escenario concreto, cuando se quiere consultar y filtrar por columna una parte de la tabla que, en comparación con toda la tabla, no es tan grande.
Volvamos a nuestro ejemplo e intentemos aplicar este índice de mapas de bits. Imagina que en nuestra tabla Customer en realidad no hay 5, sino más de 10 millones de filas. Y, supongamos que queremos filtrar nuestra consulta, con lo que obtendremos los datos de las clientas de sexo femenino con el apellido Watson.

Podemos escribir una consulta más o menos así:
SELECT FirstName, LastName, Email
FROM Customer
WHERE Gender = 2 AND LastName = "Watson";El índice de mapas de bits es ideal para esta situación, ya que, en comparación con los 10 millones de filas de registros, las filas que corresponden a un sexo determinado son mucho menos. Ahora aceleremos nuestra consulta creando un índice de mapas de bits:
CREATE BIMAP INDEX BMP_Gender
ON Customer (Gender)Y ahora seleccionamos “Kate Watson” y su correo electrónico (ver más abajo), así como todas las demás filas adecuadas de los 10 millones de esta tabla.

Un índice de mapas de bits puede ser aún más potente si lo creas en una cláusula JOIN. Por ejemplo, si unimos dos tablas: Customer y Sales, y las filtramos por sexo. En este caso, el índice de mapas de bits tendría este aspecto:
CREATE BITMAP INDEX BMP_Gender_Sales
ON Customer (Gender)
FROM Customer Sales
WHERE Customer.ID = Sales.Customer_ID;Cada vez que envíes una consulta para unir estas dos tablas y filtrarlas por sexo, estarás muy cerca del máximo rendimiento de la consulta.
Índice inverso
Un índice inverso se parece mucho a un índice normal. Pero no crea un árbol de búsqueda binario para acelerar la búsqueda de datos en orden ascendente, este índice está optimizado para la búsqueda de datos en orden descendente. La construcción sintáctica para crear un índice inverso es muy similar a la construcción sintáctica de un índice no agrupado normal. La única diferencia es que debemos indicar que los datos deben estar en orden inverso (descendente).
Supongamos que queremos optimizar una consulta con la que queremos saber los nombres de los clientes que realizaron los 3 últimos pedidos. Creemos un índice:
CREATE INDEX IX_LastOrder_Customer
ON Customer (LastOrder DESC);La palabra más importante de esta construcción es DESC. Le indica al mecanismo de SGBD que debe crear un índice inverso. De este modo, cada vez que consultemos los datos de los tres últimos pedidos de la tabla Customers, obtendremos el mejor rendimiento de la consulta.
¿Qué estructura de datos utiliza un índice?
Como ya hemos mencionado, los índices se crean junto con otras estructuras de datos para optimizar las operaciones de búsqueda. ¿Pero qué estructuras de datos son esas?
Árbol equilibrado
Los índices más comunes para acelerar las consultas utilizan, por así decirlo, entre bastidores un árbol equilibrado. La mayoría de los mecanismos de SGBD utilizan un árbol equilibrado o una de sus variantes, como un árbol b+. A continuación, se muestra el aspecto de la estructura de un árbol equilibrado normal.

El nodo superior es el nodo raíz, y todos los demás que se encuentran debajo son nodos secundarios o terminales. La búsqueda de una fila comienza en el nodo raíz. Comparamos el valor buscado con el valor del nodo actual, si es mayor o menor. Dependiendo del resultado de esta comparación, sabremos a qué lado tenemos que ir, a la izquierda o a la derecha. Si miramos el ejemplo anterior, veremos que todos los valores menores que 8 nos llevan a la izquierda, y los valores mayores que 8 a la derecha, etc.
Hash
El hash se emplea en índices para acelerar búsquedas específicas. Es una estructura de datos que proporciona una de las búsquedas más rápidas. Con el hash, los índices pueden encontrar muy rápidamente los datos que se almacenan en la tabla.
La idea principal del hash es la siguiente: en lugar de recorrer todas las claves de búsqueda con índices o buscarlas en toda la tabla, aplicamos una función hash a la clave. Esta clave de búsqueda se transforma en un valor hash que determina el “cubo” correspondiente. Veamos el ejemplo siguiente. En él, aplicamos una función hash a la clave de búsqueda “Mike”, tras lo cual se asigna un cubo/bloque determinado.
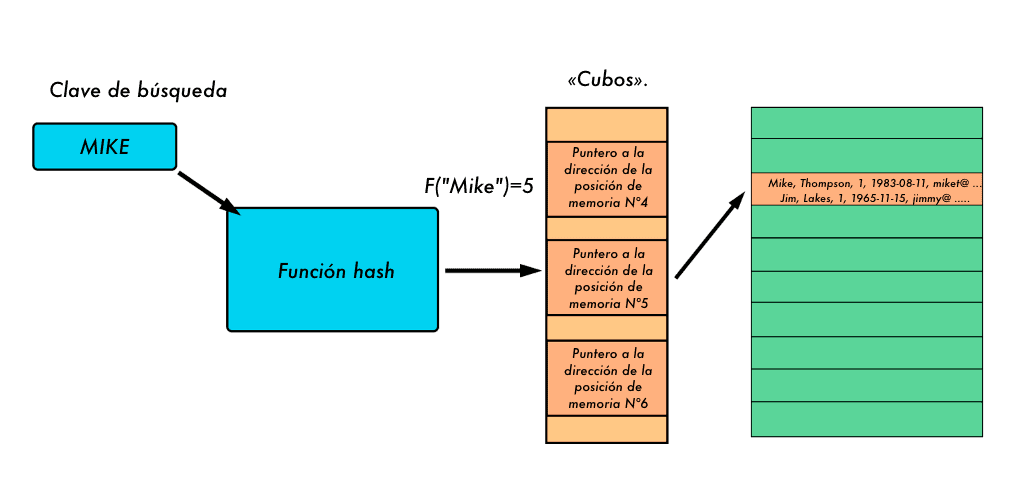
Cada uno de estos cubos en la matriz de cubos contiene la misma cantidad de registros. Independientemente de la cantidad de valores diferentes que haya en la columna, cada fila se asigna a un cubo separado. A continuación, se selecciona la fila correspondiente y se devuelve de este cubo.
Implementación de índices con mecanismos de SGBD
Como ya habrás comprendido, en una base de datos relacional hay varios tipos de índices. Y cada mecanismo de SGBD tiene sus propias implementaciones de estos índices. Recorramos los mecanismos de SGBD más populares, enumeremos los índices que tienen y analicemos cuándo es mejor utilizarlos.
Índices en PostgreSQL
PostgreSQL tiene una lista de índices bastante extensa. Cada uno de ellos es adecuado para escenarios concretos:
- El índice más común es el índice de árbol B. Será útil en situaciones en las que necesites comparar rangos en columnas que se pueden ordenar.
- El índice hash almacena un código hash de 32 bits que se deriva de los valores de las columnas indexadas. Será útil en aquellos casos en los que necesites realizar comparaciones sencillas.
- GiST no es un índice en sí mismo, sino más bien una estructura lógica en la que se pueden implementar varias estrategias de indexación diferentes. Con más frecuencia, esta estructura se utiliza en escenarios en los que necesitas encontrar el “vecino más cercano” en tipos de datos geométricos.
- SP-GiST, al igual que GiST, implementa varias estrategias de indexación. Se basa en diferentes estructuras de datos, como árboles de cuadrantes, árboles k-dimensionales y árboles básicos. Este índice se utiliza en los mismos escenarios que GiST.
- GIN también se denomina “índice invertido”. Se utiliza en escenarios en los que los datos son una matriz. El índice invertido contiene una entrada independiente para cada componente de la matriz.
- BRIN significa “Block Range INdex”, que se traduce como “índice de rango de bloques”. Se utiliza para almacenar una breve descripción de los valores en páginas de datos físicos consecutivas dentro de la tabla. Es ideal para situaciones en las que los valores de las filas coinciden con el orden físico de las páginas de datos.
Índices en Oracle
Oracle tiene una lista de índices algo menor. Pero se consideran más elaborados en cuanto a su aplicabilidad.
- El árbol B es un índice estándar. También está presente en otros mecanismos de SGBD. El árbol B es ideal para representar claves principales y columnas con una gran cantidad de valores diferentes en relación con el número total de filas.
- El índice de mapas de bits es necesario para escenarios inversos. Por ejemplo, se puede utilizar en escenarios en los que el número de valores diferentes en una columna no es tan grande en relación con el número total de filas.
- El índice por función es un índice en el que el valor que se almacena en el árbol de búsqueda se determina mediante una función. De este modo, proporciona un excelente rendimiento de las consultas en las que hay cláusulas WHERE con funciones en su interior.
Índices en SQL Server
SQL Server no tiene tantos índices, pero tienen muchas funciones.
- El índice agrupado no solo sirve para que el mecanismo de SGBD pueda realizar una búsqueda en la consulta. Reorganiza físicamente las filas en las páginas de datos para que estén ordenadas en orden ascendente o descendente.
- El índice no agrupado es el equivalente del árbol B que existe en otros mecanismos de SGBD. Principalmente, es adecuado para situaciones en las que es necesario recorrer datos con una gran cantidad de valores diferentes.
- Los índices filtrados se crean para grupos de datos específicos. Se utilizan para optimizar la búsqueda de datos asimétricos con criterios determinados. Por ejemplo, queremos encontrar el número 55 en una columna. Pero solo está en unas pocas filas (en relación con el número total de filas de la tabla). Entonces puedes crear un índice filtrado según el principio del agrupado, simplemente añadiendo la condición
WHERE column = 55.
Índices en MySQL
MySQL también tiene varios índices con los que se puede mejorar el rendimiento de las consultas.
- El índice de clave principal es un índice único con el que se puede acceder de forma rápida y eficaz a valores únicos. También es ventajosa la optimización NOT NULL, ya que no puede tener el valor NULL. Siempre se utiliza al definir la clave principal y se crea automáticamente cuando se indican las palabras clave PRIMARY KEY.
- El índice único se parece mucho al índice de clave principal. Pero es más flexible en el sentido de que permite guardar varias veces valores NULL. Se utiliza para proporcionar una unicidad adicional en caso de que ya se haya creado una clave principal.
Amplía tu conjunto de herramientas con índices de bases de datos
Si has llegado hasta aquí, ¡significa que te ha gustado leer sobre los índices de bases de datos! Espero que esta información te haya resultado útil y que hayas encontrado algo nuevo. Si tus consultas empiezan a ralentizarse, gracias a tus conocimientos sobre los diferentes tipos de índices en los distintos mecanismos de SGBD, podrás mejorar el rendimiento de las consultas.
A veces puede ocurrir que un árbol B normal no sea suficiente, o que no se ajuste al esquema o a los datos. Por lo tanto, tener una idea de los diferentes tipos de índices que hay en una base de datos relacional es como tener una navaja suiza en tu caja de herramientas.
