
¿Alguna vez te has preguntado qué hay detrás de los lenguajes que usas a diario? En este artículo analizaré brevemente cómo funcionan los compiladores y algunos lenguajes de programación esotéricos.
Al final, veremos cómo se puede diseñar e implementar un pequeño lenguaje interpretado como ejercicio práctico. Es una aventura técnica fascinante.
En nuestra época, la programación se ha vuelto muy accesible debido al desarrollo de herramientas y lenguajes de programación. Prácticamente cualquiera puede escribir un “hola mundo“, y la cantidad de frameworks para JavaScript ya es objeto de bromas.
Ahora, para destacar e impresionar a tus amigos y colegas, necesitas descender a mayor profundidad. Por eso, en este viaje, vamos a explorar cómo inventar un lenguaje de programación de broma como ejercicio práctico.
Este es un artículo simplificado que ampliará tu horizonte y, en algunos, despertará el interés y la curiosidad por sumergirse en el tema.
Cómo funciona un compilador: etapas y tipos
Al principio es necesario estudiar (o repasar) los fundamentos. Puede ser aburrido, pero es importante para la comprensión. Si quieres profundizar en el proceso técnico de traducción de código, te recomiendo que leas mi artículo sobre qué es un compilador y cómo funciona.
Un lenguaje de programación es un lenguaje formal con sus propias reglas (sintaxis), que permite registrar instrucciones (comandos) para un computador.
Los humanos han inventado miles de lenguajes de programación, pero ninguno de ellos en su forma original es “comprensible” para las computadoras, las cuales solo entienden instrucciones de máquina.
De “trasladar” el lenguaje de programación en acciones útiles se encargan programas especiales: compiladores e intérpretes.
Código de máquina: es la representación de un programa en forma binaria, que puede ser ejecutada por el procesador.
Compilador: es un programa que traduce el código fuente a instrucciones de máquina, bytecode u otro lenguaje de programación.
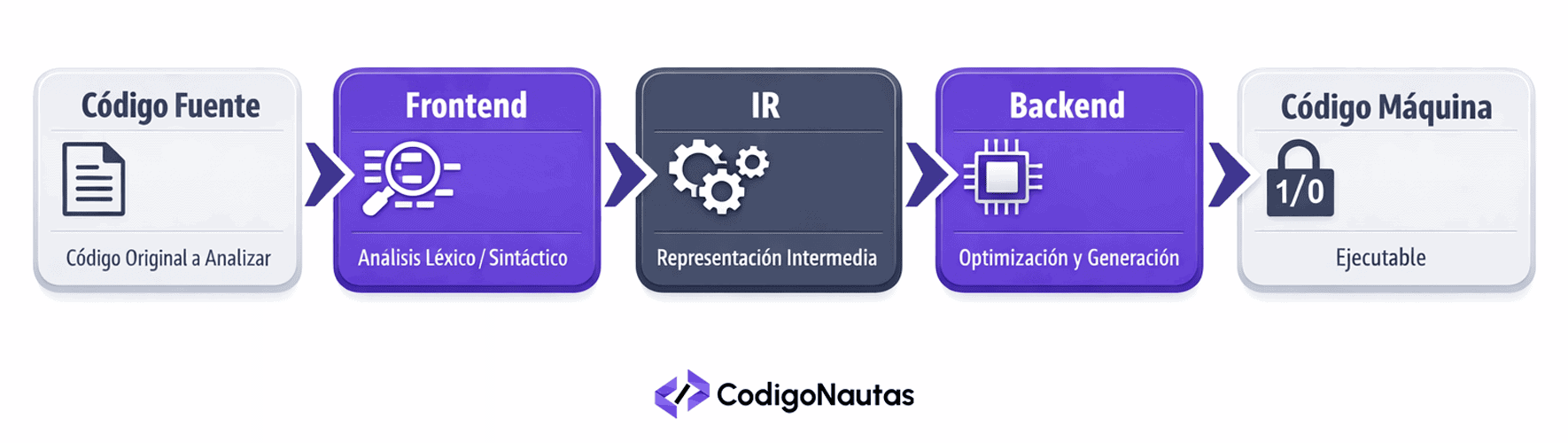
La arquitectura de un compilador moderno se divide generalmente en tres partes: el Frontend (analiza el código fuente), el Optimizador (mejora la eficiencia mediante una Representación Intermedia o IR) y el Backend (genera el código para la arquitectura específica).
Existen varios tipos de compiladores:
- Compiladores tradicionales: Convierten el código fuente en instrucciones de máquina. El resultado es un archivo binario ejecutable. Entre los compiladores tradicionales se distinguen los cross-compilers, que permiten compilar programas para otras arquitecturas y sistemas operativos. Por ejemplo, la compilación de programas para Linux en Windows es una compilación cruzada. A los compiladores tradicionales pertenecen los compiladores de los lenguajes C, C++, Pascal.
- Compiladores a bytecode: Convierten el código fuente en bytecode, comprensible para máquinas virtuales. Tales son los compiladores de los lenguajes como Java (bytecode JVM) o C# (CIL para la CLR): el compilador crea comandos no para la unidad central de procesamiento, sino para las máquinas virtuales JVM (Java Virtual Machine) o CLR (Common Language Runtime).
- Compiladores Just-In-Time (JIT): Compiladores que reciben bytecode de la máquina virtual y compilan dinámicamente las partes más utilizadas del programa a código nativo durante la ejecución. Estos compiladores se utilizan “bajo el capó” en JVM y CLR. Aunque operan de forma automática, su impacto es crítico en el diseño de sistemas de alto rendimiento, ya que el programador debe considerar el comportamiento del JIT para optimizar la ejecución.
- Transpiladores: Convertidores de un lenguaje de programación a otro. Los transpiladores se encuentran con mayor frecuencia en las tecnologías web. Por ejemplo, es popular el compilador Babel, que traduce TypeScript tipado y todas las nuevas características de ECMAScript al “viejo” JavaScript, el cual es soportado por los navegadores.
La compilación consta de varias etapas, en cada una de las cuales el código fuente se verifica y se convierte en una representación conveniente para la siguiente etapa de compilación:
- Preprocesamiento: Procesamiento de directivas del preprocesador: sustitución de macros, inclusión del contenido de otros archivos.
- Compilación: Transformación de cada archivo de código fuente en código ensamblador o en una Representación Intermedia (IR) para su optimización.
- Ensamblado: Transformación del código generado en código de máquina: archivo objeto.
- Vinculación (Linking): Enlace de varios archivos objeto entre sí y con las funciones y librerías disponibles en la plataforma de destino.
Intérprete: es un programa que ejecuta directamente un programa sin generar primero un binario independiente. En muchas implementaciones, el código fuente se analiza y se transforma en una representación interna (por ejemplo, un árbol de sintaxis o bytecode) y luego se ejecuta inmediatamente.
A diferencia de la compilación tradicional, el programa no se traduce completamente a código de máquina antes de comenzar la ejecución. Por eso algunos errores —como variables inexistentes o tipos incompatibles— pueden aparecer solo cuando el intérprete llega a esa parte del programa durante la ejecución.
Ahora tenemos un conocimiento simplificado de los fundamentos y podemos proceder al desarrollo de nuestro propio lenguaje. Pero hay tantas tecnologías y procesos, ¿por dónde empezar?
Primer acercamiento: un lenguaje en el preprocesador
Dirijámonos a las etapas de compilación. En primer lugar ocurre el preprocesamiento: la expansión de macros, lo que incluye la sustitución de los nombres de las macros por sus valores. Posiblemente hayas visto en programas en C y C++ líneas como estas:
#include <iostream>
#define TRUE 1La primera macro indica que al principio del archivo actual es necesario insertar el contenido del archivo iostream, y la segunda macro define que la secuencia de caracteres TRUE debe ser sustituida por el dígito 1.
El preprocesador sustituye unas secuencias por otras, lo que significa que puedes hacer tu propio “lenguaje de programación” sustituyendo todas las palabras clave en un lenguaje ya existente.
Como ejemplo, presento un código “claro” editado de un meme de hace más de diez años.
#include <iostream>
#include <clocale>
#define localiza setlocale(LC_ALL, "es_ES.UTF-8") // o "Spanish" si usas Windows
#define puntoycoma ;
#define entero int
#define logico bool
#define imprime cout <<
#define lee cin >>
#define uno 1
#define si if(
#define entonces )
#define esigual ==
#define sino else
#define abre {
#define cierra }
#define entra using namespace
#define principal main()
entra std puntoycoma
entero principal()
abre
localiza puntoycoma
abre
logico haySemillas puntoycoma
imprime "Hay semillas?" puntoycoma
lee haySemillas puntoycoma
si haySemillas esigual uno entonces
abre
imprime "Genial" puntoycoma
cierra
sino
abre
imprime "Te estás buscando problemas?" puntoycoma
cierra
cierra
cierraVentajas:
- Implementación muy sencilla que no requiere conocimientos específicos.
Desventajas:
- Necesitas un compilador con soporte de preprocesamiento.
- La sintaxis del lenguaje original obliga a inventar soluciones poco prácticas. En el ejemplo, las llaves compactas se convierten en palabras más largas como “
abre” y “cierra“, y el punto y coma en una macro como “puntoycoma”. - Necesitas un diccionario de sustituciones que debe aparecer al principio de cada archivo. Esto se logra ya sea con la directiva
#include, que no se puede cambiar, o usando el argumento-includeal compilar.
La solución es buena para hacer una captura de pantalla de un programa funcional y mostrársela a tus amigos. Pero el diccionario del lenguaje es parte del programa, y la compilación requiere acciones adicionales del usuario. Estas acciones pueden y deben automatizarse: pasamos del preprocesador al transpilador.
Dar el salto: crear un transpilador como YoptaScript
Si el código en C++ era solo una imagen de broma, en 2016 apareció el lenguaje de programación YoptaScript. La idea original fue llevada al absoluto: al crear las palabras clave se utilizó un diccionario de jerga delictiva.
En JavaScript no hay preprocesador, por lo que el autor implementó un programa en TypeScript que sustituye no solo las palabras clave del lenguaje, sino también los nombres de los módulos y funciones integrados.
Este lenguaje de programación utiliza tanto léxico no imprimible que es mejor no incluir ejemplos de código en el artículo que intentar editarlos. Sin embargo, si la curiosidad te llama y no temes a las groserías, en el [directorio de ejemplos del repositorio oficial hay un catálogo con ejemplos: JavaScript puro y el mismo programa en YoptaScript.
El repositorio oficial de YoptaScript en GitHub contiene todo el código fuente del transpilador.
Ventajas:
- En el marco de las tecnologías web, es un compilador-transpilador independiente que convierte el código fuente de jerga a JavaScript.
- A diferencia de la solución en el preprocesador, este transpilador permite realizar la conversión en ambas direcciones: del lenguaje original al de broma y viceversa.
Desventajas:
- Como antes, el lenguaje se construye sobre la base de sustituciones, lo que reduce su valor: sigue siendo el mismo JavaScript, pero con una carga verbal excesiva.
Conclusión: la solución es más compleja, sirve para los memes, pero se puede mejorar. Continuamos nuestro movimiento y buscamos un lenguaje de programación original.
El intérprete más simple: Brainfuck y los lenguajes esotéricos
En 1993, Urban Müller inventó el lenguaje de programación esotérico Brainfuck, que consta de ocho comandos, cada uno de los cuales se registra con un solo símbolo. Muchas implementaciones clásicas utilizan una cinta de 30 000 celdas de memoria, aunque el tamaño exacto no forma parte estricta de la especificación del lenguaje y puede variar entre intérpretes.
>— pasar a la siguiente celda de memoria;<— pasar a la celda de memoria anterior;+— aumentar el valor en la celda de memoria actual en 1;-— disminuir el valor en la celda de memoria actual en 1;.— el carácter ASCII correspondiente al valor de la celda actual;,— introducir desde el exterior un valor numérico y guardarlo en la celda de memoria actual;[— si el valor de la celda actual es cero, pasar adelante en el texto del programa al símbolo siguiente al]correspondiente (teniendo en cuenta el anidamiento);]— si el valor de la celda actual no es cero, volver atrás en el texto del programa al símbolo[(teniendo en cuenta el anidamiento).
El lenguaje es tan simple que escribir tu propio intérprete o transpilador de Brainfuck es una buena tarea para principiantes en programación. Cuanto menos azúcar sintáctico haya en el lenguaje de programación, más simple es la implementación del intérprete y más difícil es escribir programas en tal lenguaje.
Un “Hello, World” normal se ve así:
++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++.Si te interesa cuánta atención le ha dedicado la gente al lenguaje Brainfuck, te aconsejo visitar el Brainfuck Archive, donde puedes encontrar librerías de funciones, así como intérpretes y transpiladores en diferentes lenguajes, incluyendo un compilador de Brainfuck en Brainfuck. Mención aparte merecen los campeonatos de resolución lacónica de problemas.
Como siguiente en complejidad, señalaré otro lenguaje de programación esotérico: Whitespace. Para escribir código se utilizan solo tres símbolos: salto de línea, espacio y tabulación.
En este lenguaje hay 24 comandos, incluyendo operaciones aritméticas, trabajo con la pila (stack) y el montón (heap), así como comandos de control de flujo de ejecución: saltos condicionales e incondicionales a una etiqueta.
Como en el lenguaje solo hay tres símbolos, cada comando se codifica con una secuencia única de símbolos. Una característica interesante de Whitespace es la posibilidad de ocultar el código fuente del programa dentro de archivos con código fuente “normal”.
Ventajas:
- Es fácil implementar un intérprete para lenguajes con una estructura simple. Para esto se requieren habilidades básicas de programación sin conocimientos específicos.
- El lenguaje está inventado “desde cero”, por lo tanto, no se necesitan “muletas” para jugar con la sintaxis existente, como se describió anteriormente.
Desventajas:
- Cuantos menos comandos haya en el lenguaje, más difícil es escribir programas en él.
Pero esto es solo el comienzo del camino.
Inspiración para un diseño original: el lenguaje clickbait Tabloid
En 2021, Linus Lee parece que se cansó mucho de los titulares clickbait en Internet y decidió hacer un lenguaje de programación de broma en el que cada operador es un titular ruidoso.
Así apareció Tabloid. Programa para calcular los números de Fibonacci:
DISCOVER HOW TO fibonacci WITH a, b, n
RUMOR HAS IT
WHAT IF n SMALLER THAN 1
SHOCKING DEVELOPMENT b
LIES! RUMOR HAS IT
YOU WON'T WANT TO MISS b
SHOCKING DEVELOPMENT
fibonacci OF b, a PLUS b, n MINUS 1
END OF STORY
END OF STORY
EXPERTS CLAIM limit TO BE 10
YOU WON'T WANT TO MISS 'First 10 Fibonacci numbers'
EXPERTS CLAIM nothing TO BE fibonacci OF 0, 1, limit
PLEASE LIKE AND SUBSCRIBEEl lenguaje justifica completamente su idea clickbait: el encabezado de la función se declara con la expresión “DISCOVER HOW TO nombre WITH argumentos”, que se puede traducir aproximadamente como “SE HA SABIDO CÓMO nombre CON LA AYUDA DE argumentos”.
Cada variable se declara en este lenguaje exclusivamente con la participación de expertos: “EXPERTS CLAIM nombre TO BE valor”. En el lenguaje hay varias deficiencias: falta de prioridades para las operaciones matemáticas, falta de comentarios y de ciclos (puedes aprender más sobre ellos en mi artículo sobre qué son los bucles en programación).
Fuente: Playground oficial de Tabloid.
Para nosotros es interesante que el lenguaje declara soporte para variables, funciones y utiliza diferentes ámbitos de visibilidad. Esto requiere un enfoque más formal con un lexer, un parser y un árbol de sintaxis abstracta.
Explicar el código ajeno es una actividad poco noble. Tomé la implementación de Tabloid como referencia para analizar y adaptar un intérprete de un lenguaje de ejemplo nuevo.
Proyecto práctico: diseñar e implementar un lenguaje desde cero
Para este artículo analizo un pequeño lenguaje interpretado llamado Litania, inspirado en el estilo del Adeptus Mechanicus. En esta sección analizo su diseño y su implementación como ejemplo práctico de cómo se puede crear un lenguaje de programación desde cero.
Una característica curiosa del lenguaje es que el intérprete pide identificarse al inicio, y la disponibilidad de funciones depende del rango del usuario.
La implementación original del intérprete está escrita en Python (en el repositorio del proyecto se utiliza Python 3.x).
Primer paso: componer la gramática formal
Para describir las gramáticas de los lenguajes se utiliza la notación de Backus-Naur. La composición de la gramática es el primer paso en el desarrollo de un lenguaje de programación. El lenguaje natural es habitual para el humano, pero la máquina necesita una descripción estricta.
La gramática consta de dos tipos de símbolos:
- Terminales: son los elementos que aparecen directamente en el código del lenguaje (palabras clave, números, operadores, comillas, etc.).
- No terminales: son construcciones sintácticas abstractas que se van reemplazando paso a paso según las reglas de la gramática hasta obtener una secuencia válida de terminales.
En nuestro caso, es necesario reducir todos los símbolos terminales a uno solo que describa el programa. Los nombres de los símbolos no terminales están en “corchetes angulares”. Primero definiremos las unidades básicas del lenguaje: números, identificadores y constantes.
<DÍGITO> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<NÚMERO> ::= <DÍGITO> | <NÚMERO><DÍGITO>
<LETRA> ::= [a-zA-ZáéíóúñÁÉÍÓÚÑ]
<IDENTIFICADOR> ::= <LETRA> (<LETRA> | <DÍGITO>)*
<VERDAD> ::= VERDAD
<FALSO> ::= FALSO | HEREJÍA
<CONSTANTE> ::= <NÚMERO> | <VERDAD> | <FALSO>
<RANGO> ::= novicio | tecno-sacerdote | magos | archimagos
<SÍMBOLO> ::= <DÍGITO> | <LETRA>
<CADENA> ::= <SÍMBOLO> | <SÍMBOLO><CADENA>
<CADENA> ::= "<SÍMBOLO>*"Luego definiremos las expresiones aritméticas y lógicas básicas.
<UNARIO> ::= <IDENTIFICADOR> | <NÚMERO> | <CADENA> | NO <UNARIO> | <LLAMADA_A_FUNCIÓN>
<SUMA> ::= <EXPRESIÓN> + <EXPRESIÓN>
// Análogamente para todas las operaciones. Omitido por brevedad.
<EXPRESIÓN> ::= (<EXPRESIÓN>) | <UNARIO> | <SUMA> | <RESTA> | <PRODUCTO> | <DIVISIÓN> | <Y_LÓGICO> | <O_LÓGICO>Luego definiremos los operadores y funciones:
<LLAMADA_A_FUNCIÓN> ::= llamar <IDENTIFICADOR> parámetros <ARGUMENTOS>
<ARGUMENTOS> ::= <EXPRESIÓN> | <ARGUMENTOS>,<EXPRESIÓN>
<DECLARACIÓN_DE_FUNCIÓN> ::= ritual <IDENTIFICADOR> acepta <ARGUMENTOS> requiere <RANGO> <BLOQUE> terminar ritual
<BLOQUE> ::= <OPERADOR> | <BLOQUE><OPERADOR>
<ASIGNACIÓN_DE_VARIABLE> ::= que sea <IDENTIFICADOR> igual a <UNARIO>
<RETORNO> ::= volver <UNARIO>
<CONDICIONAL> ::= si expresión <EXPRESIÓN> es verdadera <BLOQUE> fin de condición | si expresión <EXPRESIÓN> es verdadera <BLOQUE> de lo contrario <BLOQUE> fin de condición
<SALIDA> ::= salida <EXPRESIÓN>
<OPERADOR> ::= <DECLARACIÓN_DE_VARIABLE> | <ASIGNACIÓN_DE_VARIABLE> | <RETORNO> | <CONDICIONAL> | <LLAMADA_A_FUNCIÓN> | <SALIDA>
<PROGRAMA> ::= <OPERADOR> | <PROGRAMA><OPERADOR> | <PROGRAMA><DECLARACIÓN_DE_FUNCIÓN>El símbolo no terminal “raíz” de la gramática es <PROGRAMA>. Si la gramática está compuesta correctamente, entonces el código de un programa sintácticamente correcto se puede reducir a este símbolo, siguiendo las reglas establecidas.
La composición de la gramática puede ser un proceso aburrido y tedioso, pero es una etapa obligatoria que permite encerrar el lenguaje natural en marcos que simplifican la escritura del código. Además, la presencia de una gramática registrada permite resaltar las palabras clave del lenguaje.
En los lenguajes de programación “normales” rara vez permiten palabras clave compuestas y utilizan el espacio como un separador conveniente. En esta sintaxis de ejemplo, para la declaración de una variable se utilizan dos palabras: “que sea”. Esto complicará un poco el lexer, pero no mucho más.
Ahora tenemos la gramática, pasamos a la escritura del código.
Segundo paso: construir el Lexer (Análisis Léxico)
La primera etapa obligatoria de un compilador es el lexer. Al compilador se le entrega como entrada el programa en forma de cadena. La unidad mínima de información en la cadena es el símbolo, lo cual es redundante para el compilador.
El lexer transforma la cadena-programa en un array de tokens. Un token es una estructura de datos que contiene una secuencia de la cadena original y meta-información útil para la siguiente etapa. En nuestro caso, se convierten en tokens separados:
- Palabras clave: “ritual”, “que”, “sea”, “fin”, “condición”, etc. Cada palabra tiene su propia representación interna única, que se utiliza en las etapas siguientes.
- Números.
- Cadenas: secuencia de cualquier símbolo encerrada entre comillas.
El lexer no verifica la corrección sintáctica del programa, solo resalta las palabras clave, constantes e identificadores.
La escritura de un lexer es una tarea rutinaria que pocos quieren hacer con sus propias manos. Con fines educativos, por supuesto, se pueden dedicar unas horas, pero lo correcto será utilizar herramientas existentes.
Para implementar un intérprete en Python, la librería PLY (Python Lex-Yacc) es la opción ideal. Puedes consultar toda su potencia en la documentación oficial de PLY. El generador de lexers requiere una lista de identificadores internos para cada token, así como una expresión regular que corresponda al token en la cadena.
from ply import lex # Palabra clave: token
reserved = {
# Asignación
"QUE": "ASSIGN_P1",
"SEA": "ASSIGN_P2",
"IGUAL": "ASSIGN_P3",
# La lista continúa...
}
class LitaniaLexer:
def __init__(self, **kwargs):
self.lexer = lex.lex(module=self, **kwargs)
# Lista de nombres de tokens. ¡Obligatorio para el generador!
tokens = [
'NUMBER',
'PLUS',
'MINUS',
'TIMES',
'DIVIDE',
'LPAREN',
'RPAREN',
'ID',
'STRING',
'COMMA',
] + list(reserved.values())
def t_ID(self, t):
r'[a-zA-Z_áéíóúñÁÉÍÓÚÑ][a-zA-Z0-9áéíóúñÁÉÍÓÚÑ]*'
val = t.value.strip()
t.type = reserved.get(val, 'ID')
return t
def t_STRING(self, t):
r'".*"'
t.value = t.value.strip('"')
return t
t_PLUS = r'\+'
t_MINUS = r'-'
t_TIMES = r'\*'
t_DIVIDE = r'/'
t_LPAREN = r'\('
t_RPAREN = r'\)'
t_COMMA = r','
def t_NUMBER(self, t):
r'\d+'
t.value = int(t.value)
return t
# Contamos líneas
def t_newline(self, t):
r'\n+'
t.lexer.lineno += len(t.value)
# Símbolos que se ignoran
t_ignore = ' \t'
# Procesamiento de errores
def t_error(self, t):
print("Símbolo no válido '%s'" % t.value[0])
t.lexer.skip(1)
# Probar la salida
def test(self, data):
self.lexer.input(data)
while True:
tok = self.lexer.token()
if not tok:
break
print(tok)Para un programa pequeño “Hola mundo” con el cálculo de una expresión simple, el resultado del trabajo del lexer será este:
SALIDA "Hola mundo"
SALIDA 2+2*2LexToken(OUTPUT,'SALIDA',1,0)
LexToken(STRING,'Hola mundo',1,7)
LexToken(OUTPUT,'SALIDA',2,21)
LexToken(NUMBER,2,2,28)
LexToken(PLUS,'+',2,29)
LexToken(NUMBER,2,2,30)
LexToken(TIMES,'*',2,31)
LexToken(NUMBER,2,2,32)El código completo del lexer ya está mostrado arriba. Puedes copiarlo directamente e instalar ply para probarlo.
Tercer paso: construir el Parser (Análisis Sintáctico)
El parser es la siguiente etapa de procesamiento del texto original. El array unidimensional de tokens se convierte en una estructura jerárquica: el árbol de sintaxis abstracta (AST). En esta etapa se verifica la corrección sintáctica del programa, es decir, el seguimiento de la gramática formal descrita anteriormente.
Sin embargo, hay un problema: la gramática descrita en la forma de Backus-Naur nos permite mezclar símbolos terminales y no terminales. El parser, en cambio, no permite eso; opera con tokens que se definieron en el lexer.
La idea, sin embargo, sigue siendo análoga: en la clase se definen funciones dentro de las cuales se describe la regla de la gramática.
import ply.yacc as yacc
class LitaniaParser:
tokens = []
# La prioridad de las operaciones se puede establecer en el parser
# Esto soluciona el problema de Tabloid con un esfuerzo mínimo
precedence = (
('left', 'LOGICAL_OR', 'LOGICAL_AND'),
('left', 'GT', 'LT', 'EQ'),
('left', 'PLUS', 'MINUS'),
('left', 'TIMES', 'DIVIDE'),
('right', 'UMINUS'),
)
def __init__(self, lexer):
self.lexer = lexer
self.tokens = lexer.tokens
def p_expr_math(self, p):
"""EXPR : EXPR TIMES EXPR
| EXPR DIVIDE EXPR
| EXPR PLUS EXPR
| EXPR MINUS EXPR
| EXPR GT EXPR
| EXPR LT EXPR
| EXPR EQ EXPR
| EXPR LOGICAL_OR EXPR
| EXPR LOGICAL_AND EXPR"""
p[0] = NodeBinaryOperation(
type=p[2],
left=p[1],
right=p[3],
)
# El parser verifica las palabras clave compuestas
# SI (IF_P1) AFIRMACIÓN (IF_P2)
def p_if(self, p):
"""IF_STATEMENT : IF_P1 IF_P2 EXPR IF_P3 CODE ENDIF_P1 ENDIF_P2"""
p[0] = NodeIfStatement(
condition=p[3], # EXPR
branch_true=p[5], # CODE
branch_false=[],
)
def build(self, **kwargs):
self.parser = yacc.yacc(module=self, start="PROG", **kwargs)Cada regla del parser acepta un argumento que permite obtener por índice la representación del token. En cada regla es necesario llenar el elemento cero de la representación. Yo utilizo inmediatamente esta posibilidad para la construcción del árbol sintáctico.
Por ejemplo, las operaciones binarias se colocan en un nodo que contiene el tipo, así como dos operandos. El árbol sintáctico se ve así:
[
{
"val": {
"val": "Hola mundo",
"node_type": "const"
},
"node_type": "output"
},
{
"val": {
"type": "+",
"left": {
"val": 2,
"node_type": "const"
},
"right": {
"type": "*",
"left": {
"val": 2,
"node_type": "const"
},
"right": {
"val": 2,
"node_type": "const"
},
"node_type": "binary_op"
},
"node_type": "binary_op"
},
"node_type": "output"
}
]
El código mostrado aquí es una adaptación educativa basada en la implementación original.
Paso final: escribir el Intérprete
El árbol de sintaxis abstracta consta de nodos que describen acciones y operandos. Mira de nuevo el ejemplo en la sección anterior. El nivel superior es un array de dos objetos. Uno por cada línea del programa. La primera instrucción consta de un nodo de tipo “output”, que contiene una constante como operando. La segunda instrucción contiene “output” con dos operaciones binarias anidadas.
La idea es simple: tomamos el primer nodo del árbol y calculamos el valor de todos los operandos, es decir, descendemos un nivel más abajo. Repetimos esto hasta que hayamos recorrido todo el árbol. Una variante mínima del intérprete que realiza operaciones aritméticas se ve así:
class LitaniaInterpreter:
def __init__(self, parser):
self.parser = parser
op = {
"+": lambda a, b: a + b,
"-": lambda a, b: a - b,
"*": lambda a, b: a * b,
"/": lambda a, b: a / b,
"MAYOR": lambda a, b: 1 if a > b else 0,
"MENOR": lambda a, b: 1 if a < b else 0,
"IGUAL": lambda a, b: 1 if a == b else 0,
"Y": lambda a, b: 1 if a and b else 0,
"O": lambda a, b: 1 if a or b else 0,
}
def eval_list(self, node_list: list[BaseNode]):
for node in node_list:
self.eval(node)
def eval(self, node: BaseNode):
if isinstance(node, NodeConst):
# Para constantes devolvemos el valor
return node.val
elif isinstance(node, NodeUnaryMinus):
# Menos unario
e = self.eval(node.val)
return -e
elif isinstance(node, NodeBinaryOperation):
# Para operaciones binarias calculamos los operandos,
# luego aplicamos la operación
l = self.eval(node.left)
r = self.eval(node.right)
return self.op[node.type](l, r)
elif isinstance(node, NodeOutput):
# Imprimimos el valor del operando
e = self.eval(node.val)
print(e)
else:
raise RuntimeError(f"Nodo del árbol desconocido: {node}")
def run(self, data):
self.parser.build()
ast: list[BaseNode] = self.parser.test(data)
self.eval_list(ast)Para almacenar el valor de las variables, en el intérprete se introduce un array de diccionarios vars, y para almacenar las funciones, el diccionario funcs. El único momento no trivial es precisamente la llamada a las funciones descritas. Una función puede declarar sus propias variables, que pueden coincidir en nombre con variables ya existentes.
Se puede excluir la intersección con la ayuda del ámbito de visibilidad: al entrar en la función se crea un nuevo diccionario en el array vars, con el cual trabaja la función lanzada. Una función puede interrumpir su ejecución en cualquier momento con el operador de retorno. En el intérprete esto se hace mediante la generación de la excepción ReturnException.
El código del intérprete pertenece al proyecto original en el que se basa este análisis.
El resultado: programas escritos en Litania
Cálculo de los números de Fibonacci (un concepto que puedes explorar más a fondo en mi artículo sobre recursión y recursividad en programación):
RITUAL fibonacci ACEPTA primero, segundo, total REQUIERE NOVICIO
SALIDA primero + segundo
SI EXPRESIÓN total IGUAL 0 ES VERDADERA
VOLVER primero + segundo
FIN DE CONDICIÓN
QUE SEA resultado IGUAL LLAMAR fibonacci PARÁMETROS segundo, primero + segundo, total - 1
VOLVER resultado
TERMINAR RITUAL
LLAMAR fibonacci PARÁMETROS 0, 1, 10El resultado es un pequeño lenguaje interpretado con estética inspirada en el Adeptus Mechanicus y con una sintaxis deliberadamente peculiar. Este proceso de validación de datos y operaciones toca temas fundamentales como la tipificación en programación, aunque en un lenguaje tan simple como Litania es muy básica.
Conclusión y próximos pasos
Escribir tu propio lenguaje de programación interpretado no es la tarea más difícil, la cual, no obstante, requiere un enfoque muy escrupuloso. Con lo que has aprendido aquí, tienes material suficiente para escribir en una tarde un pequeño intérprete de calculadora o un lenguaje de juguete similar a ejemplos como Litania o Tabloid.
Para el desarrollo de proyectos más serios es necesario sumergirse en la teoría y en herramientas más complejas. Solo toqué superficialmente el tema de los lenguajes formales y gramáticas y su clasificación. En el artículo no se consideró el tema de la optimización de código.
Si los lenguajes interpretados te parecen una “falsedad”, el proyecto LLVM tiene un tutorial de muchas páginas sobre la creación del frontend de un compilador, que permite crear código nativo. Allí todo es “de mayores”.
En términos de LLVM, el “frontend” es un programa que traduce el lenguaje de programación a bytecode LLVM IR. Luego, el “backend” traduce el LLVM IR a código de máquina para una arquitectura dada.
Litania se utilizó aquí únicamente como referencia de estudio para explicar cómo se construye un lenguaje simple. La aventura de crear un lenguaje desde cero es, sobre todo, una forma profunda de comprender las herramientas que usamos todos los días.