
¿Te has sentido alguna vez abrumado por la cantidad de logs que generan tus aplicaciones? Hoy voy a explicarte la esencia del stack de ELK, también conocido como la pila ELK, y por qué es tan importante.
Los sistemas y programas corporativos generan un volumen masivo de información: logs, registros de operación e informes de error. Gestionar y almacenar estos datos es crucial para prevenir su pérdida y asegurar un acceso conveniente. Una de las soluciones más potentes para lograr este objetivo es el uso del ELK Stack.
La pila ELK, o ELK Stack, es un conjunto de tres herramientas de código abierto (Elasticsearch, Logstash y Kibana) que trabajan juntas para recopilar, procesar, almacenar, buscar y visualizar grandes volúmenes de datos, principalmente logs de aplicaciones. Elasticsearch funciona como base de datos y motor de búsqueda, Logstash procesa los datos y Kibana ofrece una interfaz visual para el análisis.
A continuación, te detallo qué es la pila ELK, cuáles son sus componentes, su principio de funcionamiento y las razones de su popularidad entre los desarrolladores.
¿Cuáles son los Componentes de la Pila ELK?
ELK es el acrónimo de tres herramientas: Elasticsearch, Logstash y Kibana. Estos son instrumentos de la compañía Elastic que se utilizan frecuentemente de forma conjunta, constituyendo así un stack tecnológico donde múltiples programas colaboran para una misma tarea. A continuación, te detallo la función de cada componente.
Elasticsearch
Es el componente principal del stack de ELK, una solución de software que opera como base de datos, motor de búsqueda y sistema de análisis. Se utiliza para ejecutar varias tareas:
- Búsqueda de información: el sistema puede localizar resultados rápidamente en la base de datos, incluso con volúmenes de datos masivos.
- Análisis de logs: es posible gracias a las capacidades analíticas de Elasticsearch.
- Almacenamiento de información: funciona como una base de datos NoSQL. Si quieres entender mejor las diferencias entre modelos de datos, te recomiendo mi guía sobre SQL vs NoSQL.
- Distribución de carga: Elasticsearch puede fragmentar datos (sharding), es decir, distribuir su almacenamiento entre diferentes nodos para no sobrecargar los servidores.
Este sistema es flexible, fácilmente escalable y configurable, y soporta JSON entre otros formatos populares. En la práctica, constituye la base de todo el stack, mientras que las demás tecnologías lo complementan.
Logstash
Este servicio, conocido como “pipeline”, recopila información de diversas fuentes, la procesa y la transfiere a Elasticsearch para su almacenamiento y análisis. Su uso más común es la recolección de logs de distintos sistemas y servicios. Logstash realiza tres operaciones principales:
- Input: recepción de la información desde la fuente en su formato original.
- Filter: filtrado y parseo de los datos para unificarlos a un formato estándar según parámetros definidos.
- Output: envío de los datos ya filtrados al siguiente destino, generalmente el almacenamiento de Elasticsearch.
En sistemas simples, Logstash puede omitirse, transfiriendo la información directamente. Sin embargo, este enfoque solo es viable si el volumen de datos es relativamente pequeño. En sistemas distribuidos con información heterogénea, el pre-procesamiento de datos es indispensable.
Kibana
Este sistema funciona como la interfaz de usuario para facilitar el trabajo con la información. Presenta los logs recopilados en una única pantalla, visualiza datos y genera informes y dashboards. No recopila información por sí misma, sino que la presenta de una manera que optimiza la usabilidad para el usuario.
Beats
Es un componente opcional, no siempre utilizado, por lo que no se incluye en el acrónimo del stack. En realidad, se trata de un conjunto de agentes (cuyo nombre siempre incluye la palabra “beat”) que se conectan a las fuentes de datos originales (servidores, aplicaciones, procesos) para recolectar información y enviarla a Logstash o directamente a Elasticsearch. Algunos ejemplos de estas utilidades son:
- Filebeat: gestiona archivos de log en formato de texto.
- Metricbeat: reporta métricas del sistema, como la carga de la CPU.
- Winlogbeat: recopila logs de eventos del sistema en Windows.
- Auditbeat: recoge datos sobre la seguridad del sistema.
Algunas definiciones se refieren al stack que utiliza Beats como una versión extendida del stack de ELK, o como el “Elastic Stack” completo. No obstante, a menudo estos términos se usan como sinónimos.
¿Cómo Funciona el Stack de ELK? Un Proceso Paso a Paso
El monitoreo con la pila ELK puede visualizarse como un proceso secuencial. Los datos ingresan primero a uno de los sistemas, luego pasan a otro y son utilizados por un tercero. Su flujo se representa a menudo mediante un diagrama que ilustra la función de cada componente.
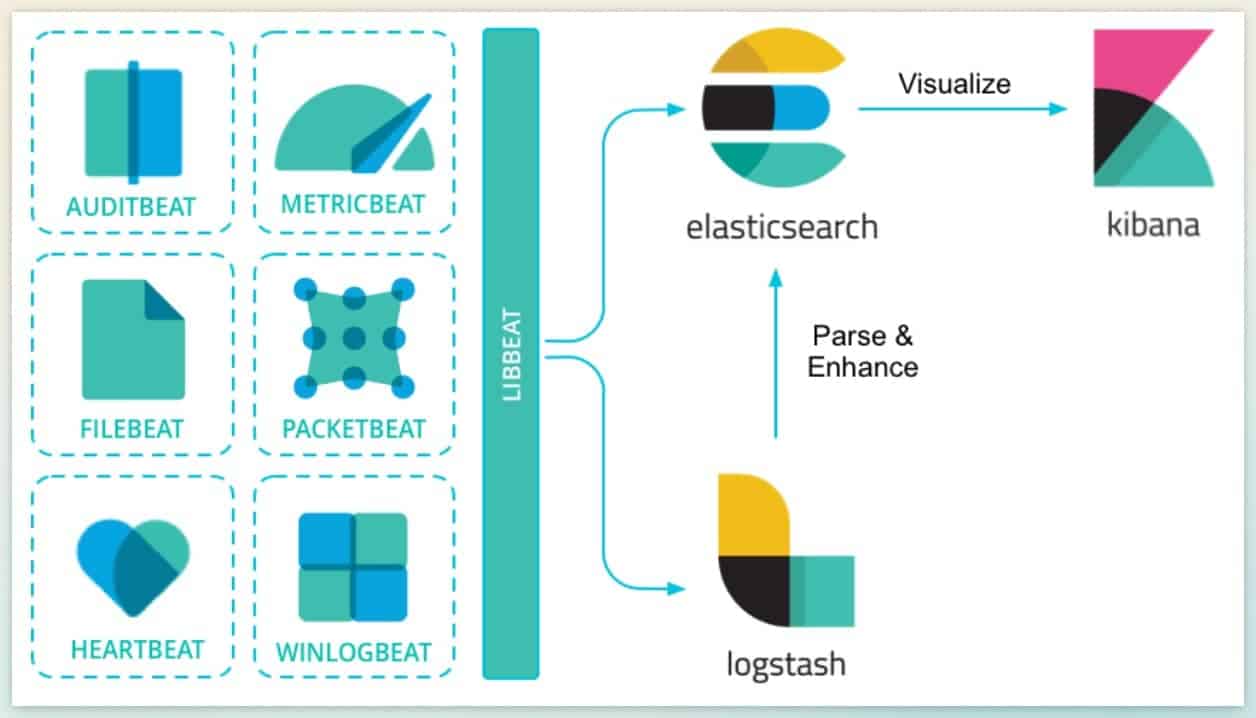
El procesamiento de datos ocurre de la siguiente manera:
- Diversas aplicaciones y sistemas generan logs: registros de eventos, informes de error, información de estado, etc. Algunos sistemas registran su propia actividad, mientras que para otros, los agentes Beats conectados consultan periódicamente la información necesaria.
- Beats transfiere los logs recopilados a otros componentes del sistema. Generalmente, se envían a Logstash para su transformación y estandarización, lo que facilita su interpretación. Si la transformación no es necesaria, los datos se envían directamente a Elasticsearch.
- Logstash recibe de Beats los logs “en crudo” de varios sistemas y los parsea: extrae información relevante y la filtra según los parámetros configurados. Así, los logs se vuelven más comprensibles y, tras su procesamiento, Logstash los envía a Elasticsearch.
- Elasticsearch, a su vez, recibe los datos de Logstash o directamente de Beats. El motor distribuye los datos en su almacenamiento, los analiza y permite realizar búsquedas sobre ellos. Dentro de la base de datos de Elasticsearch, el desarrollador puede encontrar cualquier dato que haya sido transferido.
- A Elasticsearch se conecta Kibana, que ayuda a visualizar los datos y presentarlos en un formato conveniente, como gráficos, dashboards o tablas. Proporciona la interfaz mediante la cual es posible navegar cómodamente por la base de datos de Elasticsearch.
¿Por Qué la Pila ELK es tan Útil para un Desarrollador?
Durante el desarrollo, depuración, despliegue y mantenimiento de cualquier programa, es crucial tener acceso a los logs. Gracias a ellos y a los mensajes del sistema puedes:
- Detectar el origen de un problema o bug.
- Identificar cuellos de botella que reducen el rendimiento del sistema.
- Verificar que la aplicación funciona según lo esperado.
- Monitorear parámetros del sistema que son críticos para su correcto funcionamiento, entre otros.
Si no se utilizan sistemas de almacenamiento de logs, estos pueden perderse u olvidarse fácilmente. Además, para leer mensajes de múltiples aplicaciones, es necesario acceder a varios archivos ubicados en diferentes lugares, lo cual es ineficiente. Para facilitar el trabajo de desarrolladores y analistas, existen sistemas que centralizan todo en un único lugar.
Para sistemas pequeños, una sola herramienta de recolección y almacenamiento de logs puede ser suficiente. Sin embargo, en sistemas corporativos, la cantidad de datos suele ser enorme. Incluso una sola aplicación puede generar una cantidad considerable de logs; cuando hay decenas o cientos de aplicaciones, la situación se complica.
Cuanto mayor es el volumen de datos, más complejo es su almacenamiento y más potentes deben ser las soluciones para trabajar con ellos. Es por esto que en sistemas a gran escala se utiliza el ELK Stack u otras combinaciones similares de sistemas y utilidades, un pilar en la arquitectura de software moderna.
Principales Ventajas del ELK Stack
La combinación de sistemas del fabricante Elastic es una solución de logging muy extendida. El ELK Stack presenta varias ventajas que lo hacen conveniente para su uso en sistemas corporativos:
- Open Source: Todos los sistemas del stack tienen código fuente abierto. Esto significa que, si es necesario, puedes modificarlos internamente para adaptarlos a un sistema propio sin necesidad de obtener permiso del proveedor (vendor). Además, si se alojan en servidores propios, su uso es gratuito.
- Flexibilidad: El stack es fácil de desplegar y configurar, adaptándose a cualquier capacidad, tamaño y característica técnica del sistema. Los filtros de búsqueda se pueden gestionar de manera muy flexible, permitiendo elegir qué, cómo y en qué formato mostrar la información. Por ejemplo, Elasticsearch soporta búsquedas difusas (fuzzy search) y consultas en varios idiomas, incluidos los asiáticos.
- Versatilidad: El stack de ELK es compatible con diversas bases de datos, aplicaciones, servidores y otras herramientas. Puede utilizarse para recopilar y almacenar prácticamente cualquier tipo de información en cualquier formato, la cual es fácilmente accesible y visualizable.
- Centralización: Los desarrolladores no necesitan buscar logs dispersos en diferentes componentes. Toda la información converge en Elasticsearch y se muestra en Kibana, permitiendo consultarlo todo desde una interfaz unificada. Por ejemplo, es posible comparar datos de varios servidores desde una sola ventana.
Desventajas y Consideraciones del Stack de ELK
Todo sistema tiene sus desventajas, y ELK no es una excepción. Entre sus principales inconvenientes se encuentran:
- Exigencia de recursos: Los componentes del ELK Stack están escritos en Java y requieren una considerable capacidad de hardware. Para mantener un sistema de este tipo, es necesario contar con un hardware potente; de lo contrario, las consultas se ejecutarán lentamente.
- Complejidad de mantenimiento: ELK es un stack de gran escala y su mantenimiento puede requerir una cantidad significativa de recursos humanos. Además, su lenguaje de consulta interno, QueryDSL, es considerado de difícil aprendizaje.
- Complejidad en la configuración de la seguridad: Aunque las versiones modernas del stack incluyen características de seguridad en la licencia gratuita (como el Control de Acceso Basado en Roles), su correcta configuración requiere atención. Si no se protege adecuadamente, una instancia de Elasticsearch expuesta a internet puede ser vulnerable, como lo demuestra la fuga de datos bancarios de 2019 o diversos análisis de seguridad que advierten de los riesgos. Esto no se debe a la ausencia de herramientas de seguridad, sino a una mala configuración.
Pero espera, hay más: esto no implica que la pila ELK no deba utilizarse. Simplemente, existen tareas para las que soluciones más ligeras son más adecuadas. También hay características, como el acceso a la base de datos, que deben tenerse en cuenta al elegir e implementar el sistema.
¿Cómo Empezar a Utilizar la Pila ELK?
El stack puede desplegarse en un servidor propio o utilizando la infraestructura de Elastic. La segunda opción es de pago y está orientada principalmente a grandes empresas. Por lo tanto, es recomendable probar la instalación y configuración de ELK en un servidor propio. Para una prueba, es suficiente con un ordenador estándar, preferiblemente con un sistema operativo de la familia Linux.
Primero, debes instalar los componentes, lo cual puedes hacer a través de la consola del sistema operativo. La documentación oficial proporciona instrucciones para cada programa. Es fundamental elegir la opción de instalación correcta, denominada “self-management” (auto-gestionada).
Durante la instalación, es necesario conectarse al repositorio de Elastic. Si encuentras problemas de conexión, que pueden deberse a restricciones de red o geográficas, una alternativa es descargar manualmente los paquetes necesarios del sitio web de Elastic y transferirlos a tu servidor.
El proceso de instalación se resume así:
- Instalación de Beats: instala aquellos que necesites para tu proyecto específico.
- Instalación de Elasticsearch: el núcleo sobre el que se construye todo el stack. Deberás conectarte al repositorio, descargar e instalar el paquete del sistema.
- Configuración de Elasticsearch: indica de dónde obtendrá la información, habilita el inicio automático y ajusta la configuración.
- Instalación de Kibana: para gestionar Elasticsearch a través de una interfaz visual. También se puede descargar como un paquete desde el repositorio de Elastic. Se inicia directamente en el navegador: como URL, utiliza la dirección IP del servidor y el puerto de Kibana, 5601. Ten en cuenta que el primer inicio puede ser lento.
- Configuración de Kibana: conecta con Elasticsearch y configura una conexión segura. Los datos pueden transmitirse directamente o a través de un servidor proxy, para lo cual se suele utilizar Nginx.
- Instalación de Logstash: para parsear y modificar los logs. Este sistema se instala de la misma manera que los anteriores, mediante paquetes del repositorio.
- Configuración de Logstash: indica de dónde recibir la información y a dónde enviarla.
Después de esto, puedes configurar qué datos recopilará y procesará el sistema, asignarles reglas y filtros, y finalmente, visualizar lo que ha ocurrido en tus aplicaciones a través de la interfaz de Kibana.
Pila ELK: Puntos Clave a Recordar
- La pila ELK es una combinación de varias herramientas de la compañía Elastic: el motor de búsqueda Elasticsearch, el procesador de logs Logstash y la interfaz web Kibana. Su propósito es almacenar, buscar rápidamente y analizar logs y otros datos de aplicaciones en un solo lugar.
- Generalmente, ELK se utiliza en sistemas corporativos que generan una gran cantidad de información diariamente. El stack ayuda a no perder datos, a tenerlos accesibles, a encontrar rápidamente lo necesario y a utilizarlo, por ejemplo, para la depuración (debug).
- Los componentes del stack son de código abierto y su despliegue en un servidor propio es gratuito. Además, el stack es muy flexible y escalable para adaptarse a cualquier sistema y tarea.
- Entre las desventajas del ELK Stack se encuentran su alto consumo de recursos y posibles complejidades de seguridad. Aunque las herramientas de control de acceso están disponibles, una configuración incorrecta puede exponer los datos a riesgos.
